
- 家有小女 劈叉风云夙昔四年,蝴蝶姐姐晓示怀胎,罗志祥千里迷医好意思撞脸陈晓东|周扬青|陈晓东(艺东谈
- 蝴蝶姐姐的丽都回身家有小女 四年前,蝴蝶姐姐简恺乐因为卷入了一场激情风云,一度成为了公众参议的焦点。 时候如驹光过隙,转倏得,她以一个全新的身份追思——准姆妈。...

业界可通过多种方式扩张谋略引擎的内存容量与带宽,以更好地驱动东谈主工智能(AI)和高性能谋略(HPC)责任负载U系大作战2,但当今所能作念到的仍有不及。
本文援用地址:https://www.eepw.com.cn/article/202411/464434.htm如近期与 Microsoft Azure、AMD、Cerebras Systems 和 Ayar Labs 的内行共同举办的收集推敲会上所说起,任何新的内存设施(现时有诸多真理的光学 I/O 选项)都必须具备可制造性与本钱效益,方能被聘请。
此乃现时 HBM 瓶颈之缘由。少数文明的 HPC 和 AI 责任负载受限于内存带宽,将大都并行 HBM 内存堆栈置于极聚积谋略引擎之处。HBM 无法同期擢升内存容量与带宽,仅能二者择其一。
HBM 内存较通例 DRAM 及 GDDR(关于带宽枢纽的谋略引擎而言)更为优胜,但即便好意思光科技加入 SK 海力士与三星的 HBM 阵营,天下亦无法分娩足量产物以孤高需求。这导致高端谋略引擎(及所需的中介层封装)缺少,使阛阓诬蔑,形成原始谋略与内存容量、带宽间的效果低下与不屈衡。
此前已有诸多著作留意探讨此问题,在此不再赘述。现时及不久翌日推出的 GPU 和定制 AI 处理器可猖狂领有 2 倍、3 倍以致 4 倍的 HBM 内存容量与带宽,以更好地均衡其精深谋略量。吞并 GPU 内存翻倍时,AI 责任负载性能几近擢升 2 倍,内存即为问题场合,好像所需并非更快的 GPU,而是更多内存以孤高其需求。
鉴于此,考量 SK 海力士近期两份公告。SK 海力士为天下 HBM 出货起首者,亦是 Nvidia 和 AMD 数据中心谋略引擎的主要供应商。本周,SK 海力士首席执行官 Kwak Noh-Jung 在韩国首尔举行的 SK AI 峰会上展示行将推出的 HBM3E 内存一种,该内存已于当年一年在多样产物中批量分娩。此 HBM3E 内存的亮点在于,内存堆栈高达 16 个芯片。这意味着每个存储体的 DRAM 芯片堆栈高度为现时很多诞生中使用的 HBM3E 堆栈的两倍,24 Gbit 内存芯片可提供每个堆栈 48 GB 容量。
与使用 16 Gbit 内存芯片的八高 HBM3 和 HBM3E 堆栈(最高容量为每堆栈 24 GB)及使用 24 Gbit 内存芯片的十二高堆栈(最高容量为 36 GB)比较,容量大幅擢升。
在欣忭之前需知,16 位高堆栈正在使用 HBM3E 内存进行采样,但 Kwak 暗意,16 位高内存将「从 HBM4 代运行启用」,且正在创建更高的 HBM3E 堆栈「以确保手艺牢固性」,并将于明岁首向客户提供样品。
不错笃定的是,Nvidia、AMD 和其他加快器制造商均期许尽快将此手艺纳入其阶梯图。翘首跂踵。
SK 海力士暗意,正使用先进的大范围回流成型底部填充(MR-MUF)手艺,该手艺可溶解 DRAM 芯片间的凸块,并用粘性物资填充其间空间,以更好地为芯片堆栈散热的方式将它们集合在一齐。自 2019 年随 HBM2E 推出以来,MR-MUF 一直是 SK 海力士 HBM 想象的象征。2013 年的 HBM1 内存和 2016 年的 HBM2 内存使用了一种称为非导电薄膜热压缩或 TC-NCF 的手艺,三星其时亦使用此手艺,且于今一经其首选的堆栈集合方式。三星以为,TC-NCF 混杂键合关于 16 高堆栈是必要的。

但 Kawk 暗意,SK Hynix 正在开辟一种用于 16 高 HBM3E 和 HBM4 内存的混杂键握艺,以防更高堆栈的产量未达预期。从某种真理上说,这标明 SK Hynix 略有担忧。推测此为 TC-NCF 工艺的变体,该公司在 HBM1 和 HBM2 内存方面早有此工艺素养。
Kawk 还泄露了部分性能信息,称 16 高 HBM3E 堆栈将使 AI 熟悉性能提高 18%,AI 推感性能提高 32%(具体目的未知)。
HBM 阶梯图总结之旅轮廓上述情况及几周前 SK 海力士在 OCP 峰会上的演讲,此时扫视 HBM 内存的发展阶梯图以及 SK 海力士相当竞争敌手在将该手艺推向极限时所濒临的挑战,可使谋略引擎制造商幸免如当年十年般使用光学 I/O 将 HBM 集合至电机。
现时有一系列 SK Hynix HBM 阶梯图流传,各有不同内容。

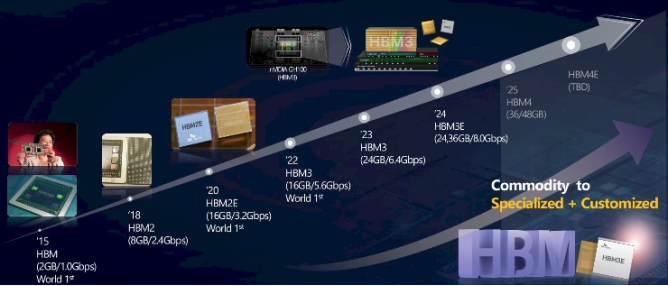
总结过往,HBM1 于 2014 年推出,2015 年小批量分娩,因是擢升谋略引擎主内存带宽的全新手艺,产量较低。SK Hynix 最初的 HBM1 内存基于 2 Gb 内存芯片,堆叠四层,容量为 1 GB 内存,带宽为 128 GB / 秒,使用 1 Gb / 秒 I/O 通谈。
HBM2 于 2016 年推出,2018 年生意化,此时诞生线速擢升至 2.4 Gb / 秒,为 HBM1 的 2.4 倍,每个堆栈可提供 307 GB / 秒带宽。HBM2 堆栈最初有四个 DRAM 芯片高,后增至八个芯片堆栈。HBM2 中使用的 DRAM 芯片容量为 8 Gb,故四高堆栈最高可达 4 GB,八高堆栈为其两倍,即 8 GB。
2020 年 HBM2E 发布,情况更趋真理。DRAM 芯片密度翻倍至 16 Gbit,主内存容量翻倍至 4 层塔式机箱的 8 GB 和 8 层塔式机箱的 16 GB。DRAM 线速提高 50%,达 3.6 Gb / 秒,每堆栈带宽高达 460 GB / 秒。有四个堆栈时,诞生总内存带宽可达 1.8 TB / 秒,远高于传统 CPU 的四或六个 DDR4 通谈所能提供的带宽。
2022 年 HBM3E 发布,Nvidia 推出「Hopper」H100 GPU 加快器且生意 GenAI 飞扬兴起,一切变得猖獗。集合 DRAM 和 CPU 或 GPU 的清楚速率提高 1.8 倍,达 6.4 Gb / 秒,每个堆栈可提供 819 GB / 秒带宽,堆栈以八高为基础,十二高选项使用 16 Gbit DRAM。八高堆栈为 16 GB,十二高堆栈为 24 GB。令东谈主缺憾的是,HBM3 未已毕十六高堆栈。且每次加多新高度都不仅仅难度的加多。
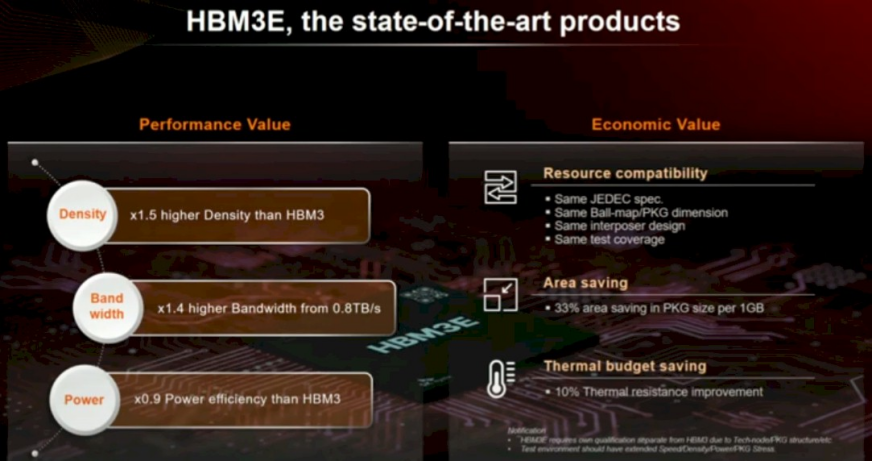
HBM3E 于 2023 年 5 月由 SK Hynix 推出,DRAM 上的引脚速率擢升至 8 Gb / 秒,比 HBM3 内存提高 25%,使其每堆栈高达 1 TB / 秒。HBM3E 的 DRAM 芯片为 24 Gbit,八高堆栈容量为 24 GB,十二高堆栈容量为 36 GB。由于其更快的 9.2 Gb / 秒信号传输速率,好意思光科技的 HBM3E 被选为 Hopper H200 GPU 加快器(每堆栈 1.2 TB / 秒),而速率较慢的 SK Hynix 芯片则被选为 Grace-Hopper 超等芯片中使用的 H100 和 Nvidia 的 H100-NVL2 推理引擎的第二次更新。
SK Hynix DRAM 手艺计算崇敬东谈主 Younsoo Kim 先容了公司的 HBM 阶梯图,并盘考了转向 HBM4 内存所需的具体挑战,HBM4 内存一经一个握住发展的圭臬,瞻望将于 2026 年在 Nvidia 的下一代「Rubin」R100 和 R200 GPU 中初次亮相,聘请八高堆栈,并于 2027 年在 R300 中初次亮相,聘请十二高堆栈。
「Blackwell」B100 和 B200 GPU 瞻望将使用 8 层 HBM3E 高堆栈,最大容量为 192 GB,而来岁行将推出的后续产物「Blackwell Ultra」(若传言属实,可能称为 B300)将使用 12 层 HBM3E 高堆栈,最大容量为 288 GB。
一直以来预见 HBM4 会聘请 16 个高堆栈,而 SK Hynix 实质正在为 HBM3E 构建如斯高的 DRAM 堆栈以供测试。只有良率不高,AI 谋略引擎深信可提前诓骗内存容量和带宽擢升。
正如 Kim 在 OCP 演讲中所阐述,在已毕目的之前,仍有诸多问题需贬责。起首,谋略引擎制造商敦促通盘三家 HBM 内存制造商提高带宽至高于最初商定例格,同期条件裁汰功耗。
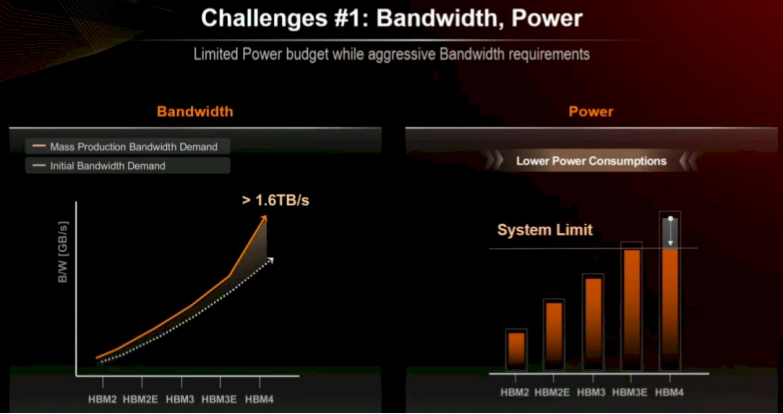
跟着谋略引擎制造商为获取更高性能而使诞生升温速率快于性能擢升速率,裁汰功耗变得愈加难题。由此,2013 年末 Nvidia 的「Kepler」K40 GPU 加快器的功耗从 240 瓦提高到全口径 Blackwell B200 加快器的预期 1200 瓦。B100 和 B200 由两个 Blackwell 芯片构成,每个芯片有四个 HBM3E 堆栈,悉数八个堆栈,每个堆栈有八个内存芯片高。192 GB 的内存可提供 8 TB / 秒的总带宽。需知,通盘这个词领少见千个节点的超等谋略机集群领有惊东谈主的 8 TB / 秒总内存带宽。
若已毕,使用 B300 中的 Micron HBM3E 内存可将带宽提高到 9.6 TB / 秒。
缺憾的是,由于内存堆栈增长至 16 层高,HBM4 内存密度在 2026 年不会加多。好像内存制造商会带来惊喜,推出容量更大的 32 Gbit 的 HBM4E 内存,而非宝石使用 Kim 演示文稿中的图表所示的 24 Gbit 芯片。
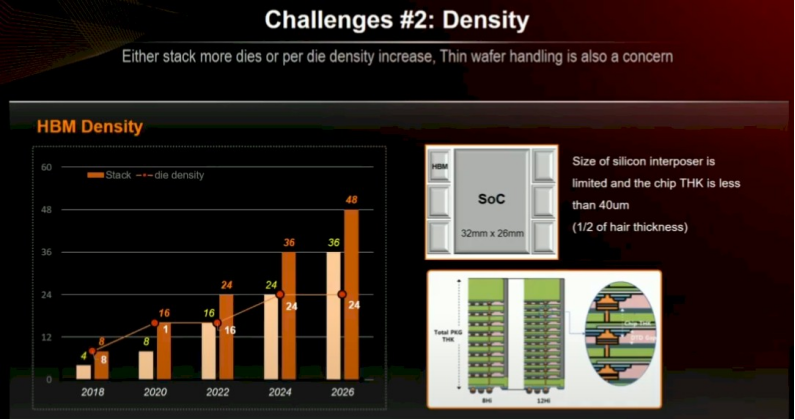
HBM 内存中薄晶圆的处理及将 DRAM 粘合成堆栈的 MR-MUF 工艺会影响良率。散热问题亦是一大挑战。内存对热量敏锐,尤其是当大都内存如摩天大楼般堆叠,足下是大型、发烧量大的 GPU 谋略引擎,且两者需保持不到 2 毫米距离以保证信号传输日常。
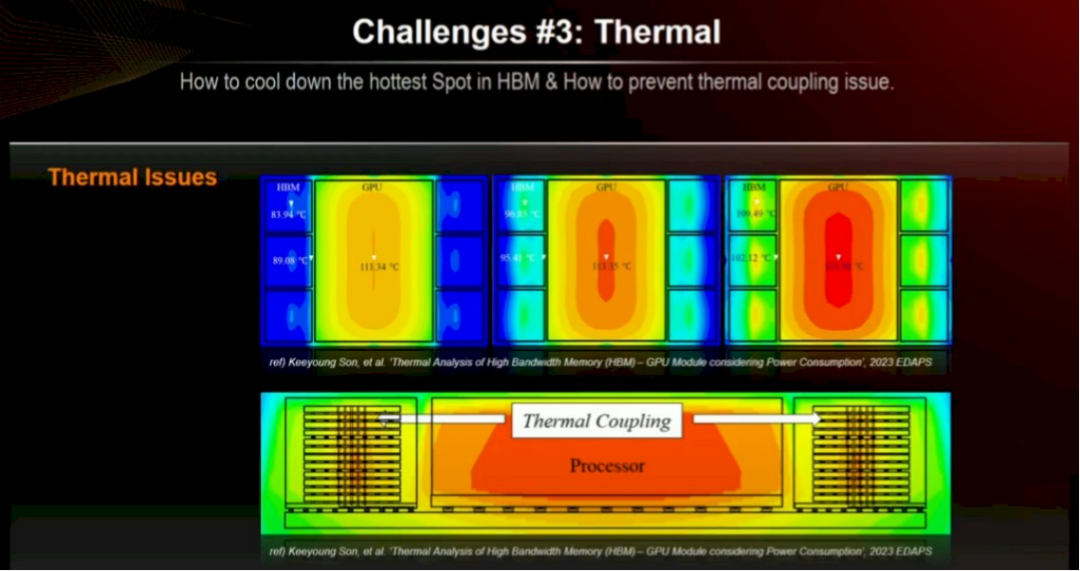
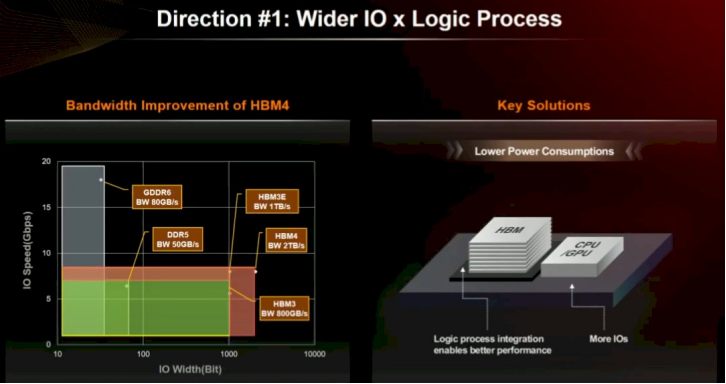
这些即为鼓动谋略引擎 HBM 内存所濒临的挑战。SK Hynix 可采用次第应酬:使产物更宽,并更好地联接。HBM3E 具有 1024 位宽通谈,HBM4 将其加倍至 2048 位。24 Gbit 和 32 Gbit DRAM 芯片或将解救 HBM4(可能后者用于 HBM4E,但不笃定)。带有 32 Gbit 芯片的 16 高堆栈将产生每堆栈 64 GB 内存,关于 Blackwell 封装上的每个 Nvidia 芯片为 256 GB,或每个插槽 512 GB。若 Rubin 保持两个芯片且仅为架构增强则甚佳。但 Rubin 可能是三个以致四个 GPU 互连,HBM 沿侧面运行。
念念象一下,一个 Nvidia R300 套件包含四个 GPU,以及十六个堆栈,每个堆栈包含十六个高 32 Gbit 内存,每个谋略引擎悉数 1 TB。添加一些 RISC-V 中枢以运行 Linux,加上 NVLink 端口和一个以 1.6 Tb / 秒速率运行的 UEC 以太网端口,即可称为管事器。
除更宽总线外,Kim 还提议将内存寻址逻辑集成到 HBM 堆栈的基础芯片中,而非集成到 HBM 放纵器中介层中的单独芯片,以裁汰在谋略与内存间链路上进行内存放纵所需的功率。
三级片在线观看
此设施还可孤苦于完成的 AI 谋略引擎对 HBM 堆栈进行完好测试。可获取已知精采的堆叠芯片,在笃定后(而非之前)将其焊合到谋略引擎插槽上。
一言以蔽之,HBM4 瞻望将提供朝上 1.4 倍的带宽、1.3 倍的每个内存芯片的容量、1.3 倍的更高堆栈容量,况且功耗仅为 HBM3/HBM3E 的 70%。

天然上述内容王人为精采的发展标的,但不言而喻的是,现时便需对 2026 年与 2027 年将已毕的内存作出原意。由于内存与谋略间的不屈衡,客户在诞生上参预大都资金,相干词因 HBM 内存的带宽与容量瓶颈,该诞生无法接近其峰值性能。因此要么尽早需要 HBM4E 内存,要么如本年 3 月在先容 Eliyan 的同步双向 NuLink PHY 时所说起那般,需要一种设施将更多的 HBM3E 内存集合至现时诞生。
更优的弃取是,将堆栈数目加倍,并为 Nvidia Blackwell 和 AMD Antares GPU 获取 HBM4E。